
Scraping Glassdoor
Glassdoor is a great site for checking out potential companies and jobs, as people can leave anonymous reviews on there. They have a decent API, but of course they don’t let you get at the most valueable part–the reviews! So, I did some Python programming to get at them for a company I applied to, and made word clouds of the top pros and cons.
The code
Glassdoor, like most sites, doesn’t like robots coming through and scraping up their valuable data. Technically, scraping is usually against the ‘terms of use’ of most websites, but if we’re only doing it for one or two companies we apply to, I don’t think it’s that big of a deal.
The code I wrote requires some manual intervention–when the site responds with a captcha, you have to refresh the Glassdoor site in your web browser. This is explained in the comments in the relevant part of the code. There are also options for automating captcha forms.
# written for python3 and tested in ubuntu 16.04
# you may need to change the cookFile variable for your cookies file location
from pycookiecheat import chrome_cookies
import os, re, lxml, requests, time
from bs4 import BeautifulSoup as bs
import pickle as pk
baseurl = 'http://www.glassdoor.com'
cookFile = os.path.expanduser('~/.config/google-chrome/Default/Cookies')
cooks = chrome_cookies(baseurl, cookie_file = cookFile)
address = 'http://www.glassdoor.com/Reviews/Pearson-Reviews-E3322.htm'
adds = [address]
address_ranges = range(2, 168) # right now pages go like _P1, _P2, etc
for add in address_ranges:
adds.append(address[:-4] + '_P' + str(add) + '.htm')
# I got these headers from inspecting the 'Network' tab in the 'More Tools'->'Developer Tools' from the Chrome menu
hdr = {'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.84 Safari/537.36',
'accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'dnt': 1,
'upgrade-insecure-requests': 1,
'accept-encoding': 'gzip, deflate, sdch, br',
'accept-language': 'en-US,en;q=0.8'
}
s = requests.Session()
# this section is for testing to make sure it works first
'''
r = s.get(adds[0], headers = hdr, cookies=cooks)
soup = bs(r.text, 'lxml')
times = []
cons = []
pros = []
reviews = soup.find(id='ReviewsFeed')
eachReview = reviews.findAll('div', class_='hreview')
for review in eachReview:
cons.append(review.find('p', class_=re.compile('cons')).getText())
pros.append(review.find('p', class_=re.compile('pros')).getText())
times.append(review.find('time', class_=re.compile('date')).getText())
print(cons)
'''
# here is the 'production' run
times = []
cons = []
pros = []
soups = [] # the raw webpage responses
for ad in adds:
cooks = chrome_cookies(baseurl, cookie_file = cookFile)
r = s.get(ad, headers = hdr, cookies=cooks)
soup = bs(r.text, 'lxml')
reviews = soup.find(id='ReviewsFeed')
while reviews == None:
# it will think you're a bot and put up a captcha page, unless you set the time.sleep to a longer time
# if you refresh the browser it will work again until the captcha page comes up
# if you're lucky, you will catch the captcha page on your browser, then it should work without interruption
print('refresh browser and hit enter')
continuing = input()
cooks = chrome_cookies(baseurl, cookie_file = cookFile)
r = s.get(ad, headers = hdr, cookies=cooks)
soup = bs(r.text, 'lxml')
soups.append(soup)
reviews = soup.find(id='ReviewsFeed')
reviews = soup.find(id='ReviewsFeed')
eachReview = reviews.findAll('div', class_='hreview')
for review in eachReview:
cons.append(review.find('p', class_=re.compile('cons')).getText())
pros.append(review.find('p', class_=re.compile('pros')).getText())
times.append(review.find('time', class_=re.compile('date')).getText())
print('completed', ad)
#time.sleep(3)
# saves the data locally for more analysis later
pk.dump(soups, open('soups','wb'))
pk.dump(cons, open('cons','wb'))
pk.dump(pros, open('pros','wb'))
pk.dump(times, open('times','wb'))
Next we need to do the analysis of the words. For this I used the Natural Language Tool Kit (nltk) and then made some word clouds on wordle.net.
# written for python3 and tested in ubuntu 16.04
from nltk.corpus import sentiwordnet as swn
import pickle as pk
from nltk.sentiment.vader import SentimentIntensityAnalyzer # need to do 'pip3 install twython' for this to work properly
import nltk
from nltk.collocations import *
import string
bigram_measures = nltk.collocations.BigramAssocMeasures()
trigram_measures = nltk.collocations.TrigramAssocMeasures()
# need this if haven't downloaded yet
# nltk.download('sentiwordnet')
# nltk.download('wordnet')
cons = pk.load(open('cons', 'rb'))
pros = pk.load(open('pros', 'rb'))
times = pk.load(open('times', 'rb'))
# kind of neat sentiment analysis
#sid = SentimentIntensityAnalyzer()
#ss = sid.polarity_scores(cons[0])
conwords = []
prowords = []
for con in cons:
tempWords = nltk.word_tokenize(con)
for word in tempWords:
conwords.append(word)
for pro in pros:
tempWords = nltk.word_tokenize(pro)
for word in tempWords:
prowords.append(word)
conwords_np = [word for word in conwords if word not in string.punctuation]
conFreqs = nltk.FreqDist(conwords_np)
proFreqs = nltk.FreqDist(prowords)
# this is another way to score ngrams
'''
bg_cons_fd = nltk.FreqDist(nltk.bigrams(conwords_np))
bg_cons_fd_top = [{bg:cnt} for bg,cnt in bg_cons_fd.items() if cnt>50]
finder = BigramCollocationFinder(conFreqs, bg_cons_fd)
finder.apply_freq_filter(10)
scored = finder.score_ngrams(bigram_measures.raw_freq)
'''
'''
for word, freq in conFreqs.items():
if freq>50:
print(word, freq)
'''
#finds top 10 2 and 3-grams in pros and cons
banned_2grams = [('A', 'lot'), ('It', '\'s'), ('do', 'n\'t'), ('has', 'been'), ('If', 'you'), ('what', 'they'), ('in', 'terms'), ('you', '\'re'),
('can', 'be'), ('if', 'you'), ('ca', 'n\'t'), ('wo', 'n\'t')]
# definately a smarter way to avoid stupid ngrams using parts of speech, but that's for another time
confinder2 = BigramCollocationFinder.from_words(conwords)
confinder2.apply_freq_filter(10)
contop10_2grams = confinder2.nbest(bigram_measures.pmi, 10)
con_scored_2 = confinder2.score_ngrams(bigram_measures.pmi)
con_2g_cleaned = []
for i in con_2grams_sorted:
add = True
for j in i[0]:
if j in list(string.punctuation) + ['I', '\'ve']:
add = False
if i[0] in banned_2grams:
add = False
if add == True:
con_2g_cleaned.append(i)
con_2grams_sorted = sorted(con_2g_cleaned, key = lambda x: x[1])
contop20_2grams_sorted = con_2grams_sorted[-20:]
contop20_2grams_sorted.reverse()
contop20_2grams_sorted
confinder3 = TrigramCollocationFinder.from_words(conwords)
confinder3.apply_freq_filter(10)
contop10_3grams = confinder3.nbest(bigram_measures.pmi, 10)
con_scored_3 = confinder3.score_ngrams(bigram_measures.pmi)
#protop10_3grams = profinder3.nbest(bigram_measures.pmi, 10) # this method doesn't include the score value
con_3grams_sorted = sorted(con_scored_3, key = lambda x: x[1])
contop20_3grams_sorted = con_3grams_sorted[-20:]
contop20_3grams_sorted.reverse()
profinder2 = BigramCollocationFinder.from_words(prowords)
profinder2.apply_freq_filter(10)
protop10_2grams = profinder2.nbest(bigram_measures.pmi, 10)
pro_scored_2 = profinder2.score_ngrams(bigram_measures.pmi)
pro_2g_cleaned = []
for i in pro_2grams_sorted:
add = True
for j in i[0]:
if j in list(string.punctuation) + ['I', '\'ve']:
add = False
if i[0] in banned_2grams:
add = False
if add == True:
pro_2g_cleaned.append(i)
pro_2grams_sorted = sorted(pro_2g_cleaned, key = lambda x: x[1])
protop20_2grams_sorted = pro_2grams_sorted[-20:]
protop20_2grams_sorted.reverse()
protop20_2grams_sorted
profinder3 = TrigramCollocationFinder.from_words(prowords)
profinder3.apply_freq_filter(3)
pro_scored_3 = profinder3.score_ngrams(bigram_measures.pmi)
#protop10_3grams = profinder3.nbest(bigram_measures.pmi, 10) # this method doesn't include the score value
pro_3grams_sorted = sorted(pro_scored_3, key = lambda x: x[1])
protop20_3grams_sorted = pro_3grams_sorted[-20:]
protop20_3grams_sorted.reverse()
# normalize weights for a nice appearance in wordle
maxW = max([gram[1] for gram in contop20_2grams_sorted])
minW = min([gram[1] for gram in contop20_2grams_sorted])
contop20 = []
for gram in contop20_2grams_sorted:
contop20.append([gram[0], (gram[1]-minW+5)/(maxW-minW)])
maxW = max([gram[1] for gram in protop20_2grams_sorted])
minW = min([gram[1] for gram in protop20_2grams_sorted])
protop20 = []
for gram in protop20_2grams_sorted:
protop20.append([gram[0], (gram[1]-minW+5)/(maxW-minW)])
# export to file for use in http://www.wordle.net/advanced
with open('cons 2 grams worlde.txt', 'w') as writeFile:
for gram in contop20:
writeFile.write(' '.join(gram[0]) + ':' + str(gram[1]) + '\n')
with open('pros 2 grams wordle.txt', 'w') as writeFile:
for gram in protop20:
writeFile.write(' '.join(gram[0]) + ':' + str(gram[1]) + '\n')
Results
Finally, the fun part! I went to wordle.net and made these word clouds. These span reviews all the way back to 2008, so I’ll have to filter out the more recent reviews soon, and see what it looks like since 2013. They changed CEOs in 2013 to John Fallon, and the “brave, imaginative” phrase (in the 3-grams with punctuation) is part of a “brave, imaginative, and decent” thing that the former CEO, Marjorie Scardino, was all about.


I filtered out the junk 2-grams, but haven’t done so yet for 3-grams, so they have some useless phrases in there.


Seems like some of the pros are tuition reimbursement, being laid back, making your own schedule, a resume builder, changing lives, and another one that wasn’t quite in the top 20 was ‘work from home’.
On the con side, work life balance is a problem, low compensation, and being out of touch is mentioned. Funny that work-life balance showed up in pros and cons.
You can see I need to filter out useless phrases, like ‘A lot of’, etc.
On Pearson
Pearson is a giant multinational corporation that is mostly involved in education and publishing. They are, in fact, the largest education company and publisher in the world! I had never even heard of this company until I applied to a job there, but that’s because they own loads of brands that I had heard of–like Penguin Books, Prentice Hall, Addison Wesley, and a score of others, and don’t seem to use the Pearson name often.
Their reviews on Glassdoor have been steadily going down:
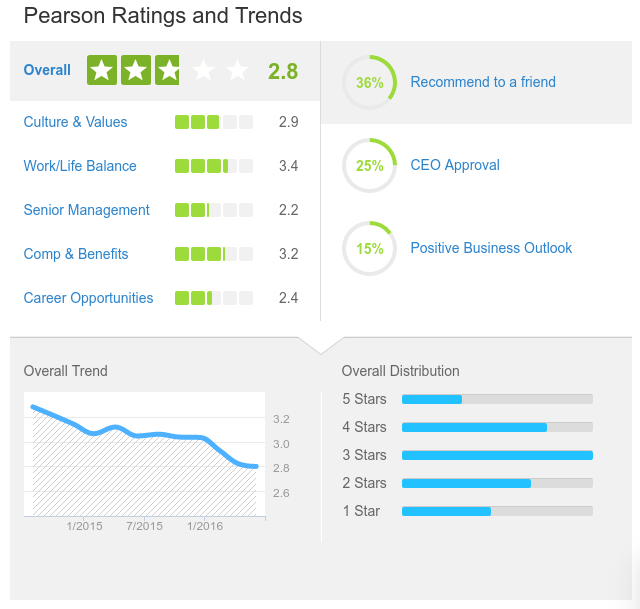
Only 25% of people from the company approve of the CEO, and only 36% recommend working there to a friend. Yikes! There was a massive restructuring in the last few year though, as everything is moving from print to digital. Loads of people were laid off, and that doesn’t bode well for reviews. However, if your skills are in the digital realm, they’re interested in you!