
Summary
As machine learning becomes more advanced, we’re moving from our local computers to more powerful machines. An example is high-powered GPU machines for neural networks. These machines can be thousands of dollars to build, and difficult to maintain. An example is the machine shown in the cover photo for this story, which is one of the beefy GPU lab machines at Regis.
The GPU rigs are crucial for taking advantage of recent deep learning breakthroughs. This includes things like recognizing cancer cells in brain scans, detecting pneumonia from X-rays, or something more fun like classifying dog breeds.
In this post I’ll overview a GPU high-performance computing (HPC) cluster I created for student and faculty use at Regis, and show how only a few GPUS can be used by dozens of people to schedule and run neural network training jobs.
Background
Regis’ data science program is doing well and is expanding. One side effect of this is that many new courses are being developed. One such course is the deep learning course (MSDS686), which requires the use of GPUs to run heavy neural network calculations for things like image classification. An example of this is Microsoft’s COCO challenge, where objects are classified (labeled) and even segmented (outlined) within an image. In order to successfully create an algorithm that can do this, you need a huge amount of data, and a huge amount of calculations performed on that data to train a neural network to do the classification and segmentation.
Free GPU/TPU resources
At first, the course used Google’s Colab, which offers free GPU use. This works great, but has many limitations. For example, importing large amounts of data doesn’t work well, and you can only use the GPU for something like 12 hours straight before it shuts down your access and you have to restart training. Another option is Kaggle’s kernels, which allow for GPU and TPU (tensor processing unit) instances. Again, there are time and data limitations like with Colab. A better solution is to have a dedicated GPU system students can use for the course.
One big problem is GPUs can only be used to train one neural network at a time. In other words, if you have 10 students that want to train their nets and only 5 GPUs, 5 of the students can train at a time, and the other 5 will have to wait. The solution I found to this is to use a HPC software with job scheduling. This allows people to create a Python or other script file and submit it in a queue to run on the GPUs. The software I ended up settling on is SLURM, which is a free and open-source software for HPC with job scheduling.
Implementation
I wanted to use Ubuntu as the base OS for the systems, since it seems to be the top choice for personal and server Linux systems these days. There wasn’t much out there in the way of instructions for implementing SLURM with GPUs on Ubuntu, so I documented my steps as a went. It first took several days to get everything working. Then after the Regis cyberattack, the machines were moved to a different campus and networks locked down. This caused problems and took several more days of debugging and modifying settings to get things working again.
How it Works
The system can be accessed via NoMachine for a GUI, but it’s best used through SSH in a console. This means any data transferred to or from the system can be done with SCP or wget for downloading data onto the system. Running jobs is done with a Python (.py) file/script:

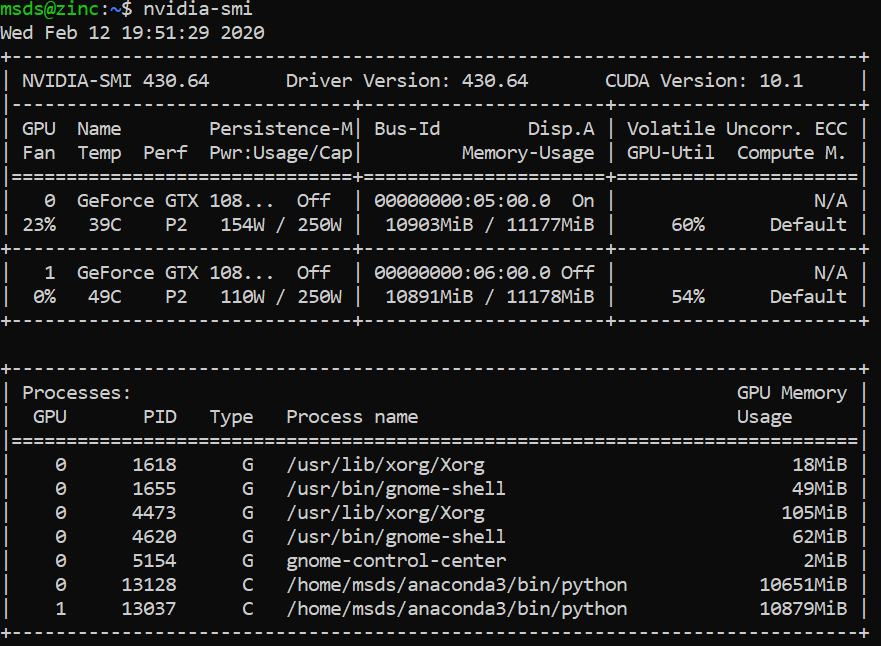
Once the job is running, you can monitor it with SLURM and look at GPU utilization with nvidia-smi:
The benefit of such a system is that we can schedule a huge number of jobs to run, and they will run in the order of submission (albeit with some priority given to higher-priority accounts). This means classrooms of 20+ students can utilize a handful (6) of GPUs to run their calculations and neural net trainings. One caveat, however, is that students have to learn the Linux command line, SSH/SCP, and may have to do some debugging to get things working. The neural net trainings need to be run from .py files, and the trained neural net weights should be saved to a file then exported to another location with SCP. However, these are great skills to learn, so I don’t feel bad making students go through that process.
Conclusion
There were lots of little details that are documented in the GitHub instructions. User creation entails important caveats and details. For example, you want to set HDD usage limits for users, users have to be created and synced across machines (I used FreeIPA), and users have to be created and deleted within the SLURM system separately from the OS. Networking, firewalls, and ports also entail some gotchas, as well as debugging. Everything I’ve learning is documented in my instructions.
Overall, it’s been a good learning experience, but difficult and painstaking. Another option I didn’t discover until I was far through the process is using OpenHPC’s recipes, which should guide a person through installing SLURM and other HPC software on a SLE or CentOS system. However, I’m not sure how well-made or complete the instructions are, and since Ubuntu is the system I have most experience in, I prefer to use that when possible. If you’re building a HPC GPU, feel free to leave a comment or questions below, or to contact me about it.